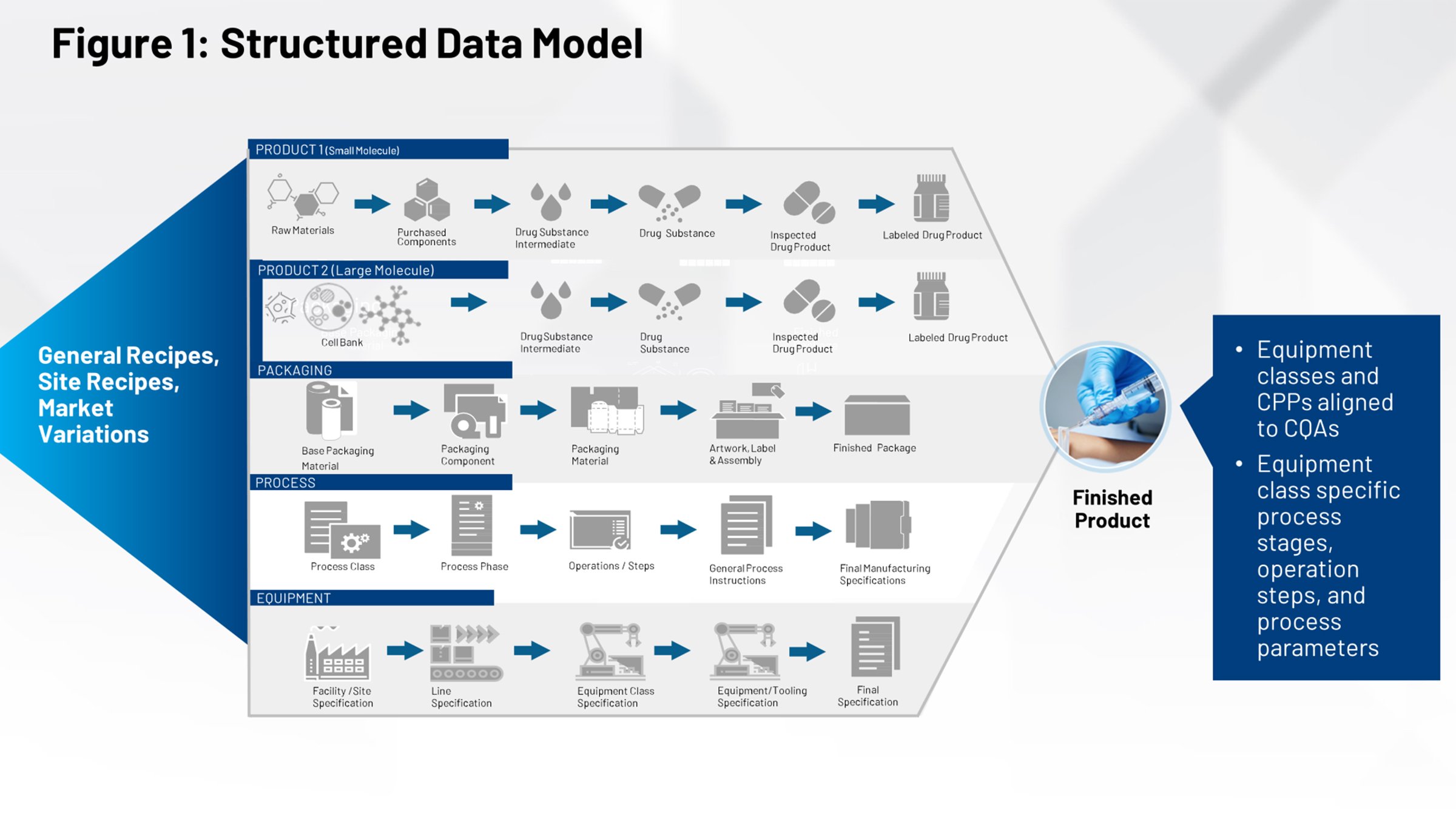
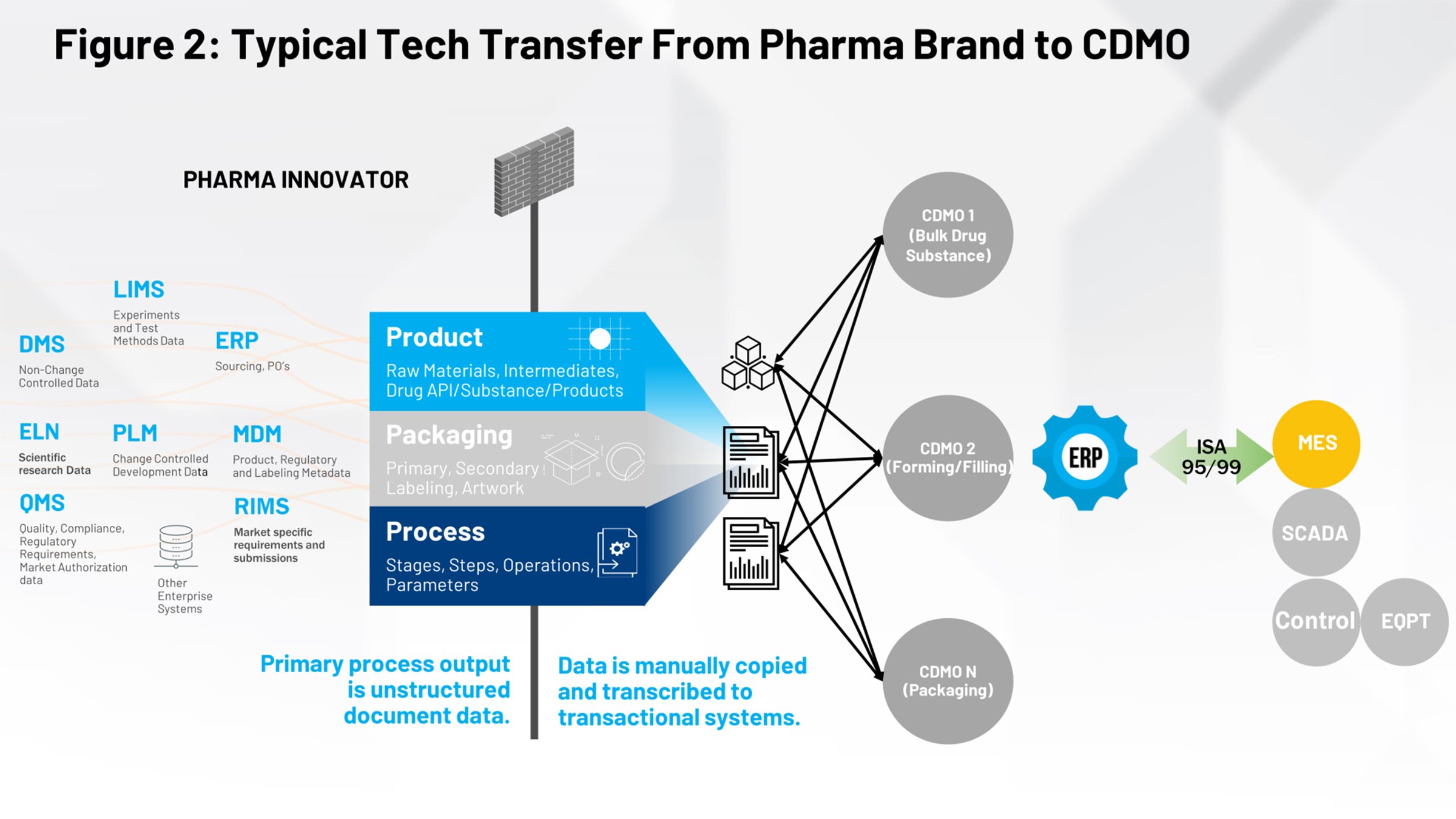
La Figura 2 ilustra el proceso actual de transferencia de tecnología que debería resultar familiar a quienes trabajan en la industria de las ciencias biológicas. En el lado izquierdo están todos los sistemas que contribuyen a la definición del producto, el envasado y el proceso. Todo esto tiene que ser canalizado mediante un cortafuegos y ser recibido por un grupo de fabricación interna o por varios fabricantes contratados que tienen que interpretar la parte que les corresponde de la información.
Nuestra misión es habilitar la conversión de estos documentos en vidrio o basados en imágenes en algo estructurado y repetible que se pueda entregar de manera uniforme a los sistemas flujo abajo para eliminar el elemento humano de interpretar la intención del documento. Posteriormente, todos los socios flujo abajo pueden aprovechar los datos.
Cómo lo hacemos
Si analizamos el proceso para cumplir esta misión, primero necesitamos asegurarnos de que los datos se envíen de forma segura. Muchas empresas se comunican por FTP, correo electrónico, llamadas telefónicas y sitios web, por lo que resulta difícil proteger la propiedad intelectual desde el punto de vista de la estrategia de control. A fin de cuentas, todo lo que fluye a través de la transferencia de tecnología es propiedad intelectual de su empresa que se debe proteger, y tiene que estar disponible para las partes interesadas adecuadas en el momento adecuado.
No se trata solo de la conversión de los datos, sino también del seguimiento de esos datos. Se necesita un registro de auditoría para que, en caso de un evento adverso, pueda comprender exactamente los datos que se convirtieron, quién lo aprobó, quién lo concluyó, quién recibió los datos y quién los utilizó.
Alguien es responsable de recolectar toda la información de todos los sistemas diferentes que usan los científicos y los ingenieros de desarrollo de procesos. Después hay que agregarla a un solo documento o a un compendio de documentos y orquestar el proceso de entregar los datos a la organización de fabricación.
Lo que falta es un mecanismo de conversión y orquestación como Google Translate que comprenda la verdadera intención de lo que se intenta comunicar mediante la transferencia de tecnología y lo convierta en algo predecible y aprovechable.
La idea es que, una vez analizados los datos en un formato comprensible y reutilizable, los sistemas flujo abajo no necesitarán que seres humanos introduzcan toda la información. Por el contrario, la información se transferirá automáticamente al sistema que la necesite.
Nuestra intención es utilizar un mecanismo de procesamiento de lenguaje natural que comprenda los documentos –el contexto de las palabras, la semántica, la intención gramatical– y que disponga de un algoritmo de aprendizaje automático que pueda comprender la intención de cada documento y convertirlo a un formato estructurado ISA 88. Básicamente, reúne los documentos y los enlaza entre sí con datos digitales para elaborar un núcleo de datos digitales reutilizables que sus sistemas puedan digerir fácilmente.
Pero los documentos de transferencia de tecnología no solo utilizan datos digitales o de texto con formato jerárquico o de tablas. También tienen datos de imágenes. Podrían incluir análisis de cromatografía. Podría haber métodos de muestreo y de pruebas. Estos conjuntos de datos no estructurados no se pueden convertir fácilmente en datos digitales. Pero estos conjuntos están relacionados hasta cierto punto con los datos digitales, por lo que es necesario poder entender las diferencias inherentes entre los diversos conjuntos de datos que puedan estar enterrados en un documento.
Cuando el documento se procesa con la herramienta de procesamiento de lenguaje natural, puede recoger imágenes escaneadas y utilizar las tecnologías de reconocimiento óptico de caracteres (OCR) para extraer datos. O bien, si se han originado como datos digitales capturados en un documento PDF, los datos pueden volver a extraerse.
En este punto, no hay ningún contexto detrás de esos datos. La herramienta simplemente extrae los datos y dice: “Entiendo el volumen de datos que existe en este documento”. El resultado del procesamiento de lenguaje natural busca los indicadores clave para poder crear conjuntos de datos tabulares que se puedan importar o introducir fácilmente en el sistema flujo abajo.
Uno de los beneficios de este enfoque es la colaboración que permite. Es muy difícil colaborar con alguien en un documento en PDF si un valor se lee incorrectamente. ¿Cómo se comunica esto? Puede enviar un correo electrónico para decir: “Hola: en la página 22, párrafo 3, línea 4 hay un valor que no puedo leer”. Si usted puede extraer eso, la capa de inteligencia puede indicarle lo que falta o es capaz de resaltar las partes a las que se debe prestar atención para poder hacer el proceso mucho más eficiente.
Elegir una ruta
Hay dos caminos que se pueden tomar. Uno consiste en continuar haciendo lo mismo que ahora porque entiende ese proceso. En la industria de las ciencias biológicas, es muy difícil impulsar el cambio. Por tanto, se puede continuar trabajando con organizaciones de desarrollo y hacer que produzcan los mismos PDF que han estado elaborando durante años y, posteriormente, utilizar una capa de proceso de lenguaje natural para convertir los datos a un formato digital, reutilizable y legible. Este es uno de los caminos.
El segundo camino consiste en adoptar herramientas digitales nativas que permitan modelar el proceso y los materiales en las primeras fases del proceso de desarrollo y publicar los conjuntos de datos digitales de forma nativa. Somos realistas porque sabemos que tomará años, si no décadas, para que las soluciones digitales nativas se adopten en ciertas áreas de la industria de las ciencias biológicas.
Mientras tanto, promovemos este enfoque de dos pasos: comenzar por utilizar el poder de computación de la inteligencia artificial y del aprendizaje automático para convertir los documentos en algo reutilizable y, después, adoptar herramientas digitales nativas a lo largo del tiempo. El mayor beneficio es esencialmente la eficiencia en el trabajo, pero va más allá de eso:
- Mayor rapidez en los ensayos clínicos, la comercialización y las autorizaciones de comercialización (variaciones o sabores)
- Menor costo total de las transferencias internas y externas a fabricación
- Mayor velocidad y eficiencia en la validación del proceso
- Menos tiempo de espera del aprovisionamiento/puesta en marcha de la instalación, la línea y los equipos
- Mejor calidad del lote, y menos desechos y desperdicios
- Mayor velocidad de las presentaciones de solicitudes y aprobaciones reglamentarias
- Mejor calidad del bucle cerrado por diseño, desde el desarrollo hasta la fabricación y el cumplimiento normativo
- Mejor rastreabilidad de la genealogía del lote (país adecuado, producto adecuado)