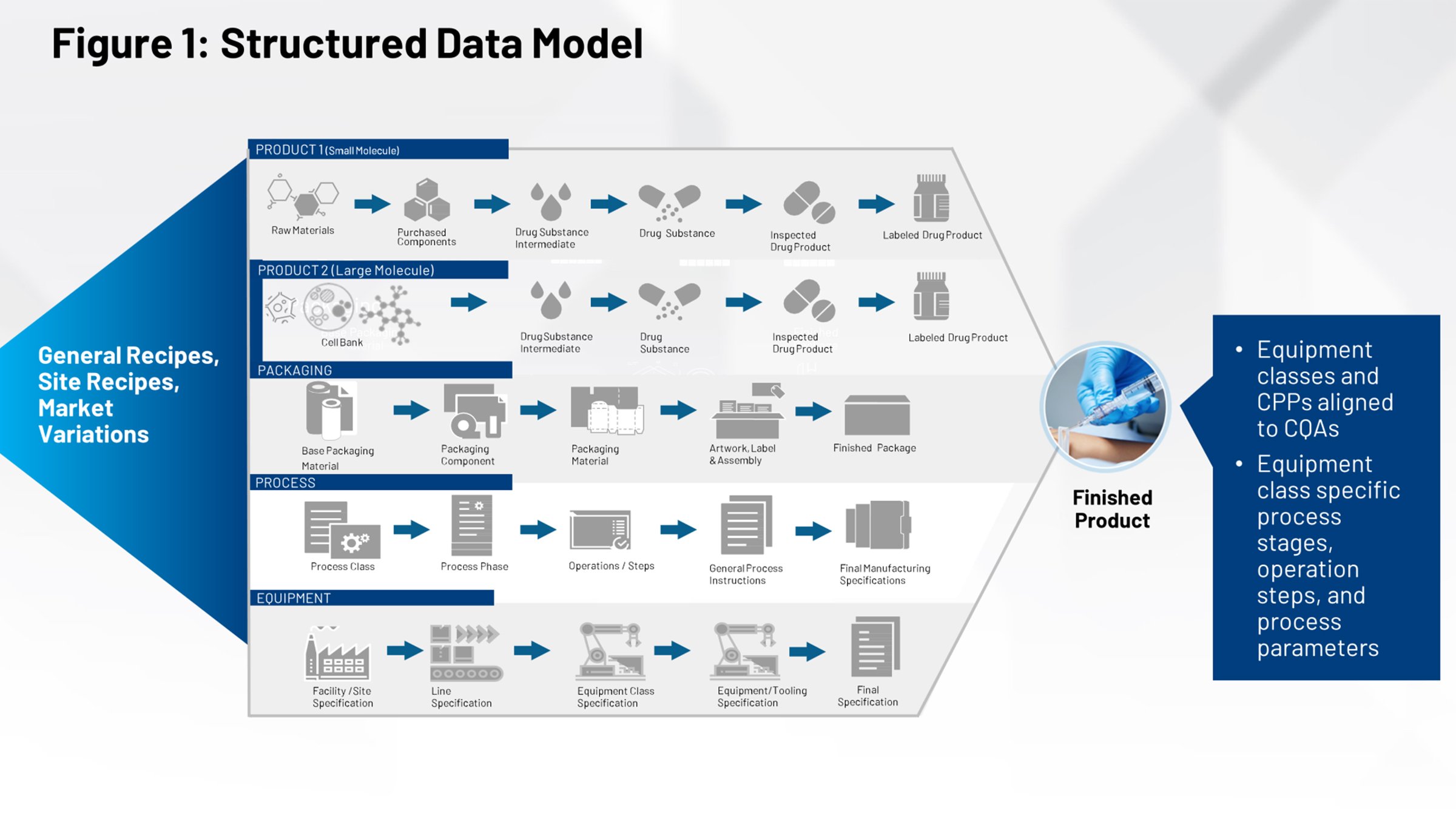
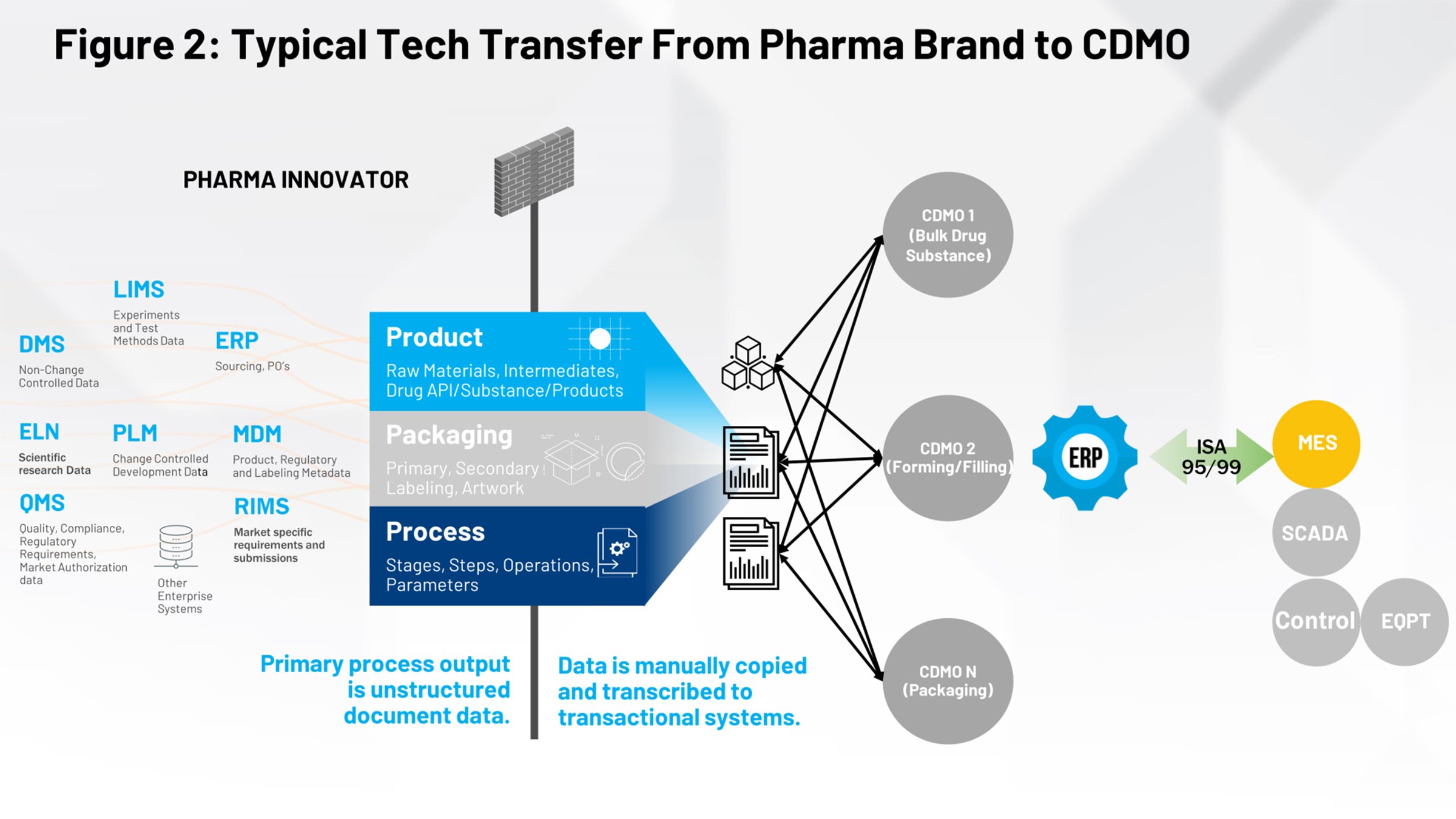
Figure 2 illustrates the current tech transfer process that should be familiar to those of us in the life sciences industry. On the left-hand side, you have all the systems that contribute to the definition of the product, the packaging and the process. All of that needs to be funneled through a firewall and received either by an internal manufacturing group or multiple contract manufacturers that need to interpret their relevant piece of information.
Our mission is to enable the conversion of these paper-on-glass or image-based documents into something structured and repeatable we can consistently provide to downstream systems and remove the human element of interpreting the intent of that document. Then the data can be leveraged by all downstream partners.
How we do it
Looking at the process for accomplishing this mission, first we need to ensure the data is securely submitted. Many companies communicate via FTP, email, phone calls and websites, and it becomes very difficult from a control strategy perspective to secure intellectual property (IP). At the end of the day, everything that flows through tech transfer is your company’s IP that must be secured and made available to the right parties at the right time.
It’s not just about the conversion of the data; it’s also about tracking that data. You need an audit trail in case of an adverse event so you’re able to understand exactly what was converted, who approved it, who signed off on it, who received the data and who consumed the data.
Somebody is responsible for collecting all the information from all the different systems being uses by the scientists and the process development engineers. Then they need to aggregate it into a single document or maybe a compendium of documents, and orchestrate the process of delivering the data to their manufacturing organization.
What’s missing is that orchestration and conversion mechanism like Google Translate that understands the true intent of what you’re trying to communicate through tech transfer and turns it into something predictable and leverageable.
The idea is that once it parses the data into an understandable, reusable format, the downstream systems won’t require humans to type in all the information. Instead, the information is automatically pushed to the system that needs it.
Our intent is to use a natural language processing mechanism that understands the documents — the context of the words, the semantics, the grammatical intent — and has a machine-learning algorithm that can understand the intent of each document and convert it to an ISA 88 structured format. Essentially, it takes the documents and stitches them together with digital data to come up with a reusable digital data construct your systems can readily ingest.
But tech transfer documents don’t just have digital or textual data formatted in tables or in hierarchies. They also have image data. There might be chromatography analysis. There might be sampling methods and testing methods. These are unstructured data sets you can’t easily convert to digital data. But they’re related to some level of digital data, so you need to be able to understand the inherent differences across different datasets that might be buried in that document.
When you run the document through the natural language processing tool, it can take scanned images and use optical character recognition (OCR) technologies to extract data. Or, if it happens to have originated as digital data that got captured in a PDF document, it can pull the data back out again.
At this point, there’s no context behind this data. The tool has simply extracted the data and said, “I understand the volume of data that exists in this document.” The natural language processing output looks for key indicators so we can create tabular data sets that can be readily imported or ingested by the downstream system.
One of the benefits of this approach is the collaboration it enables. It’s very hard to collaborate with someone on a PDF document if a value is misread. How do you convey that? You send an email and say, “Hey, on page 22, paragraph three, line four has a value I can’t read.” If you’re able to extract that, the intelligence layer can tell you what’s missing or is able to highlight the pieces you should pay attention to so you can make the process much more efficient.
Choose a path
There are two directions through this. One is to continue doing what you’re doing today because you understand that. In the life sciences industry, it’s very hard to drive change. So you can continue working with development organizations and have them produce the same PDFs they’ve produced for years, and then use a natural language processing layer to convert it into something digital and reusable and legible. That’s one pathway.
The second pathway is to adopt digital native tools that allow you to model the process and materials very early in the development process and natively publish the digital data sets. We’re realistic in that we know it will take years — if not decades — for certain corners of the life sciences industry to adopt native digital solutions.
In the interim, we’re promoting this two-pathway approach: Start by using the computing power of AI and machine learning to convert documents into something that’s reusable, and then over time adopt digital native tools. The biggest benefit is pure labor efficiency, but it goes beyond that to:
- Improved speed to clinical trials, market and market authorizations (variations or flavors)
- Reduced overall cost of internal and external transfers to manufacturing
- Increased speed and efficiency of process validation
- Reduced latency of facility, line and equipment provisioning/start-up
- Improved batch quality, and reduced scrap and waste
- Improved speed of regulatory submission and approvals
- Improved closed loop quality by design from development to manufacturing to regulatory
- Improved traceability into batch genealogy (right country, right product)